The Second Coming of the Search Engine
• Jannik Siebert • 8minWe are all familiar with the term search engine. They have been around almost as long as most remember the internet. From their primitive beginnings, search engines have come very far. Searching has become synonymous with web browsing. In fact, "search" is a first-class functionality of any modern web browser. The search bar is a search bar more than a URL bar — whether it's recommending searches or searching our habits for visited sites.
Humans adapt amazingly fast. We quickly forget how clunky things used to be. Big tech companies have spent their last few decades optimizing search engines. Things haven't always been this way — let's go back about 80 years.
Search Engine Origins
The year is 1945. A researcher, by the name of Vannevar Bush, has been working on a hypothetical device: the memex, which was introduced in the historical essay "As We May Think".
"Consider a future device … in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to their memory." — Vannevar Bush
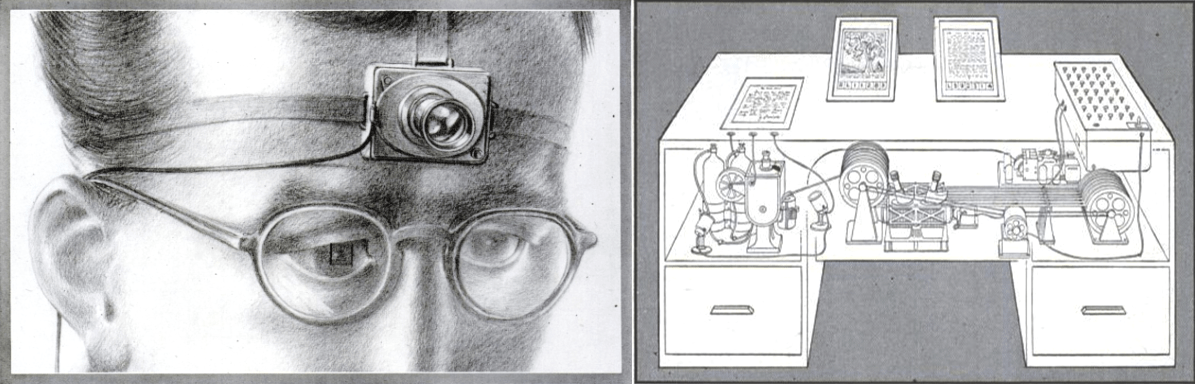
Vannevar imagined the possibilities of a device that could store any knowledge via a camera mounted on the operator's forehead. The memex literally photographs everything the operator sees. After capturing, the knowledge would be available by typing mnemonic codes or consulting a code index. The idea for the memex was established largely based upon microfilm, which was thought of as advanced technology of the future.
In a way, the memex (or at least a part of it) was the first search engine to be thought of. Vannevar goes even further and envisioned an encyclopedia of the future, based on a network of documents connected by association — somewhat analogous to hyperlinks.
Well, the memex was never built. So, let's skip ahead a few decades — back to big tech companies. The thing is: they weren't always that big. Larry and Sergey (the founders of Google) initially developed their PageRank algorithm in 1996 at Stanford.

Since then, information retrieval researchers have been busy. Search engines have profited from novel approaches, such as collaborative-filtering in recommender systems (e.g., Netflix recommendation based on behavior of other users). Some of the approaches are more simple than others. For example, the anchor text trick was the mere realization that links referring to a website often describe the website better than the website's content itself. These improvements didn’t really change how search engines search, but rather how they rank results. They still search for the keywords that you give them — at most considering synonymous meaning.
It is safe to say that search engine indexing "understands" webpages a lot better than in the early PageRank days. How exactly all this works, at this point, is a safe-guarded secret.
In any case, modern search engines are pretty great at showing people what they want to see. But, naturally, even the greatest search engine hits its limits...
Limitations of Discovery
Modern search engines are great at discovery — that's what they were built for. However, "recall" is a very different story. Try using Google to find: that funny tweet about cats I saw two weeks ago, or that private note on memory techniques I saved somewhere. These are things we know exist somewhere but have lost our path to. We might often want to find back to them, rather than discover them…
So, how do we solve this problem? We will focus on this limitation, in particular, considering humans themselves are pretty bad at recall. The human brain and search engines work quite differently. Vannevar already mentioned this in his seminal essay. The brain operates by association. If we can grasp one thing, we snap to the next by the paths of thought. However, our memory isn't everlasting and paths that aren't traversed frequently start to fade. An effective human index requires a lot of awareness in one's own thought process (metacognition); this is the reason books don't work for most.
Now, we could train our own memory for better recall — many have done so and compete in memory competitions. But that seems a bit overkill and we believe most would definitely prefer a more lazy solution.
Some have gone to solve this problem by tending to their own digital gardens of knowledge, involving different ways of note-taking, flash cards, and reiteration to build a second brain. If you are among these, augmenting your mind, please don't stop! Note-taking and (spaced) repetition are among the best ways of stimulating your metacognition.
Unfortunately, most are not among these digital gardeners. It takes effort to arrive at the point of consistent and valuable note-taking. A solution involving less effort might be building our own index with bookmarking. Hierarchical thinking has been digitally drilled into our thoughts. Our digital files are organized into nested folder structures. We could simply bookmark everything we want to recall into a nice clean structure. Sounds simple, right? But we've probably all had moments when we didn't know where to place a file, or the hierarchy was just wrong. Folders are an old concept not fit for the digital world. Bookmarks based on tags might be closer to how we actually think. In any case, bookmarking is great, if, and only if, we bookmark. But what do we bookmark? What do we wish to index?
As our personal data becomes increasingly digital, the need for better recall grows.
A Shift in Perspective

Vannevar believed we could learn from the associativity and semantic understanding of the human brain. It turns out this is precisely what a fairly new technology is great at: transformers, a machine-learning model using neural networks based on attention. You might have heard of ELMo, BERT, or GPT-3. These are transformers that can "understand" the semantics of text very well. This allows them to be used in next-sentence prediction (aka text generation), question answering, and much more.
Most notably here, transformers allow us to compare items with accurate similarity. An item doesn't necessarily have to be text though. For example, the search engine same.energy allows users to search for images based on similar style. The maker, Jacob Jackson, has also made a demo search engine for style of tweets. This isn't a search engine that works well for the query "funny tweet". Instead, you would input an example of a funny tweet, to find other similar funny tweets.
The possibilities of accurate semantic similarity search have only recently become possible. They require text transformers (invented around 2018) and recent advances in computing hardware (cheaper and more powerful GPUs).
A Step in the Right Direction
For the last year, I have been thinking about personal search engines a lot. Search engines that would, like a memex, index everything relevant we see. The need for this was born of a personal problem. I would frequently think about tweets or articles that I would like to revisit or share. But most of the time I could only remember a few keywords or rough concepts (I won't be entering any memory competitions any time soon).
When reading about tools for thought, digital gardens, and second brains, I always thought: "Wow! I want that, but I don't want to spend time building that."
Our knowledge and personal data are becoming increasingly digital. I am often annoyed by how spread out my personal reading consumption history is. I have about 1,000 articles in Pocket, 1,500 bookmarks in Raindrop, and more than 10,000 favorited tweets — just to name a few things that I could somewhat want to remember.
Introducing…
mmry — a personal search engine. Over the last 6 months, I have spent weekends working on the proof-of-concept. With mmry I want to remove the friction of indexing and enable accurate recall. I am already digitally interacting with most things that I want to remember: favoriting tweets, adding articles to Pocket, starring repositories on GitHub, writing notes in Notion; the list goes on. These interactions can automatically and regularly be captured and added to my personal index, allowing me to recall information at any time. That's exactly what mmry does — creating a personal search engine.
I have finally decided to announce mmry, in view of the recent spotlight on the topic. Last month, Linus Lee introduced his universal personal search engine Monocle. This sparked discussion on Hacker News and the release of a few similar projects. After a great conversation with Linus, I decided to share mmry and continue building more publicly, as far as that does not hinder the progress of mmry.
Personal search engines might not transform thinking or metacognition radically, but they would provide recall — a step in the right direction.
Building a Skateboard
At the moment, mmry is a skateboard: a minimum viable product to validate decisions. At mmry, we still need to explore architecture, performance, and ergonomics of search. The experience should be as frictionless and fast as possible. Nevertheless, I have been using mmry daily for the last months — it works 🚀 (and was a great help when I was writing this essay).
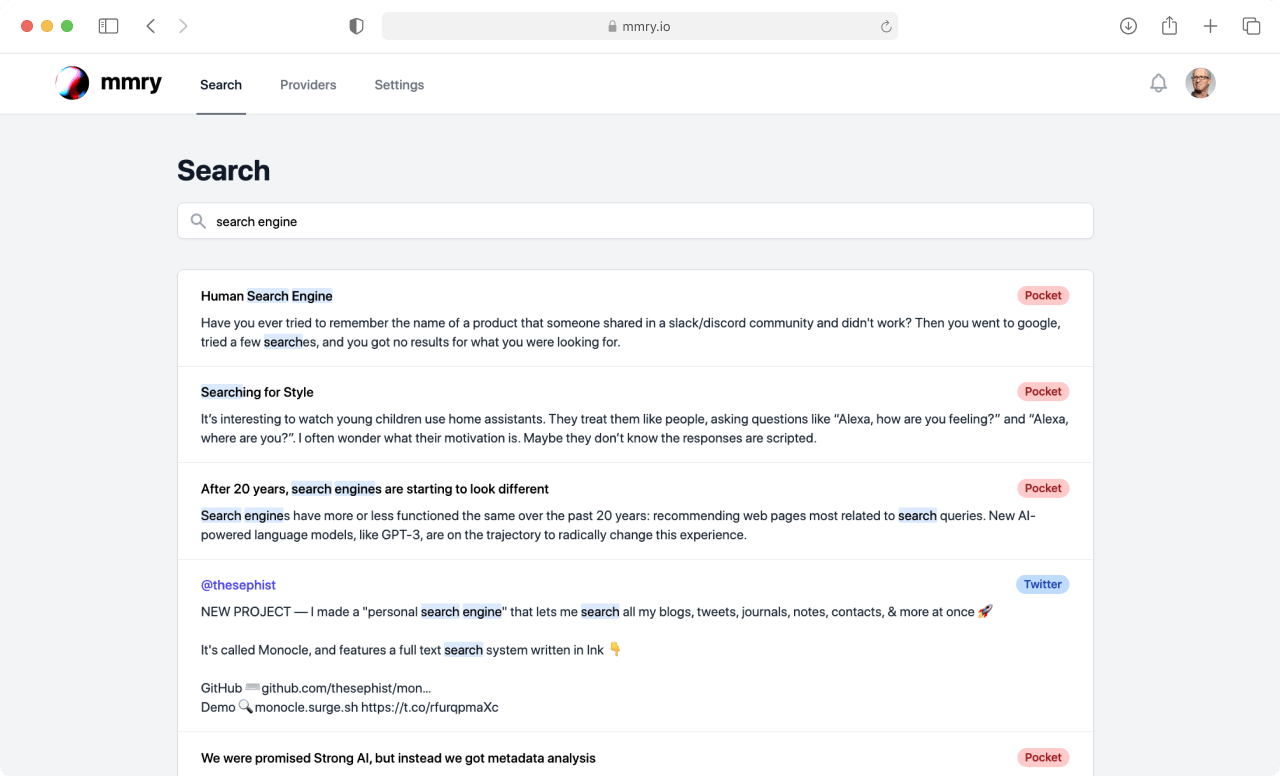
The UI is still very basic and meant to be a plain wireframe. Currently, you can add providers of documents (e.g. Twitter, Pocket) to be indexed. Then, the backend (in the cloud, for the moment) regularly indexes your data via APIs of those providers. And, of course, a search bar (as we know it) allows for search.
We will be adding providers for all sorts of tools and services. In the pipeline are: Raindrop, Notion, GitHub, Evernote, and more. Feel free to let us know if you have ideas for interesting providers.
Evolving Recall
Keeping personal data safe is very important to us. mmry will cost money — in our industry that's a good thing. mmry will never monetize private data. We have a natural distrust towards big tech companies. We are also exploring further possibilities for safer search. There may be possibilities for encrypting documents and only keeping gibberish indices or semantic vectors online. Future versions might include a self-hosted option for mmry that works in private clouds or on personal computers.
The first version of mmry is a proof-of-concept. It turns out solely keywords and synonyms work quite well if you're not indexing the whole web. However, we are also experimenting with similarity and association measures using optimized transformers, as well as related technologies. There is a lot to explore…
Epilogue: An Open Standard for Personal Data
Privacy, portability, and ownership are fading. We wish to address this in part by architecting a standard around personal data and online interactions. GDPR and similar laws have given us some rights, but there is still much to do. Data exports are far from perfect. A standard might be able to forge new ideas and processes around digital personal data. More on this, hopefully soon…
Related Work
- Monocle: Universal, Personal Search Engine
- APSE – A Personal Search Engine (HN): Probably the closest thing to Vannevar's forehead-mounted camera.
- Apollo (HN): A Unix-style personal search engine
- A Memex in Ruby: An advanced and in-depth data hoarding and search tool.
- my mind: A smart bookmarking tool without hierarchy.
- Building a search engine from scratch: A tour of the big ideas powering our web search.
Follow the journey of mmry. I would also love to hear your thoughts on the topic.
This essay and further work on mmry is inspired greatly by Linus' Monocle introduction.
The step to building more publicly is also inspired by Steve Ruiz's attention to detail and ability to share amazing progress.
Did I miss anything or have any typos? Hit me up…
References
- The Atlantic — As We May Think
- Wikipedia: Microfilm
- Wikipedia: PageRank
- IR Conference
- Wikipedia: Collaborative Filtering
- Google — How Search Works
- CNET — Google's fight to keep search a secret
- The Guardian — Good luck in making Google reveal its algorithm
- Springer — Metacognition, comprehension monitoring, and the adult reader
- Andy Matuschak — Why books donʼt work
- GatesNotes — Moonwalking with Einstein
- Wikipedia: World Memory Championships
- Maggie Appleton — Digital Gardening
- Maggie Appleton — Gardening History
- Andy Matuschak — Note-writing systems
- Andy Matuschak — About
- Linus Lee — Incremental note-taking
- Michael Nielsen — Augmenting Long-term Memory
- How to Make Yourself Into a Learning Machine
- Maggie Appleton — Building a Second Brain
- Douglas C. Engelbart — Augmenting Human Intellect: A Conceptual Framework
- Nicky Case — How to Remember Everything
- Matuschak, Nielsen — Timeful Texts
- Tobias van Schneider on Folders
- Wikipedia: Transformers
- arXiv: Attention Is All You Need
- same.energy
- t.same.energy
- Jacob Jackson — Searching for Style
- Linus Lee — Twitter
- Linus Lee — Monocle
- Hacker News: APSE
- Hacker News: Apollo
- Henrik Kniberg — Making sense of MVP
- Shawn Wang — Keyboard First
- Brad Dickason — Speed is the killer feature
- arXiv: RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Image: TED Conference
- Image: Tom Coe — Unsplash
- Image: Barthelemy de Mazenod — Unsplash
If you've made it this far… Here's a sneak peak of logo exploration for mmry.